LLMs for parsing unstructured data (IIT Course Planner v2!)
Happy new year! IIT Course planner (the course dependency graphs) used to be (and probably still is) the only reason people used to visit my blog. So much that it accounts for more views than any other webpage, except the homepage, and outdoes my next most popular article by 2x
It’s also no secret that I was working on a successor for the course planner for a while. The previous article had stowed the graphs right at the end, as an appendix of sorts, and people had to scroll down all the time. So I’ll make that easier this time.
TL;DR: If you’re here for the successor, go here. It’s still a work in progress.
Contributors?
There were 6 open things I wanted people to work on when it came to the initial release, which can be seen on the README. This was committed on Mar 2, 2022 and it has been almost two years since then.
In two years, I’ve got no contributors for these issues.
This is not a typo. I don’t know if I should be flattered, because I did it so nicely in the first go or if I should be disappointed because everyone except ES1 has access to these, and AM1/MS1 have pretty terrible diagrams because their courses were newly introduced. I did get one text from one interested person to add the ES1 dependencies, but that never materialized into anything.
Not having enough motivation to get the wheels rolling on v2, I tugged at my ex-roommate1 (who is now the overall coordinator of DevClub), and asked him if he could get some interested contributors.
Teamwork
My seventh semester was hectic, to say the least. I was trying to push a publication out while simultaneously applying to grad school, doing courses and TAing a course (also why I didn’t blog much). While I do think I got a good team, I barely got any time to scope out the project, do the scaffolding and add boilerplate code so most of them could take the project forward. I think only one guy came forward, forked my old repo and repurposed the pipeline to work on the 2023-24 courses of study. I didn’t pay much heed to this until my semester was over, when I realized I should probably have a look. Cloning and playing with the extraction code gave me some clean results. The recommmended course extraction was not great, but I hacked something together in a few that seemed to work. Unfortunately, this person was busy with a wedding and then with other things, so Sisyphus was now carrying this rock alone up the hill.
Sisyphus, though, wanted to drop the rock and let it roll down the hill while he enjoyed his last few months of being an undergraduate. Aditya didn’t like that.
“Kuch toh results dikha de”
“Yaar I can give it 20 hours. I think kuch toh nikal jayega but not promising anything”
Data pipeline
I had learnt a lot from last time, and that can roughly be summed up in 3 lines:
- No Jupyter Notebooks
- No XML, use JSON
- Manual labour where neccessary, LLMs where impossible
So the first task was porting the pipeline from Jupyter to bash, and exporting the details to JSON files. I drew up a small schema and got the data saved for both courses and programmes to their respective JSON files.
The next step was extracting the recommended courses. I semi-automated this. Table recognition has advanced a bit more since the last time I wrote the script, and since our table had lines, img2table made it easy. It wasn’t perfect, though. The results still had to be manually verified. In hindsight, GPT-4V or LLaVa would be a good model to automate this process. But that’s too much ML too early in the game, without good reason.
I had the course database and program data cleaned up in 5 hours, and the rest to kill on building the UI. While I am a better frontend engineer now than I was last year, I didn’t want to do frontend yet.
Which finally brings us to the title :)
LLMs as parsers for unstructured data
To motivate the problem, consider a data extraction task. Suppose we need to go from a table to a JSON:
"recommended": [
[
+------+--------+--------+--------+--------+ "COL100",
| Sem1 | COL100 | ELL101 | PYL101 | MTL100 | "ELL101",
+------+--------+--------+--------+--------+ "PYL101",
| Sem2 | APL100 | CML101 | MCP100 | MTL101 | "MTL100"
+------+--------+--------+--------+--------+ -> ],
| Sem3 | COL202 | COL215 | COL106 | MTL106 | [
+------+--------+--------+--------+--------+ "APL100",
| Sem4 | COL216 | COL226 | COP290 | ELL205 | ...
+------+--------+--------+--------+--------+ ],
...
]
Because the input and output structure are well-defined, it’s easy to write a program that traverses the table row by row and accumulates the courses. However, if the input structure is not well-defined, or is mostly in natural language, the task becomes a bit more interesting. Consider extracting course prerequisite relations from text.
CLL251, MCL242, ESL760 -> [CLL251 && MCL242 && ESL760]
AML701/AML734/CEL719/MEL733 -> [AML701 || AML734 || CEL719 || MEL733]
If every course relation was defined so cleanly, this would also be a structured data extraction problem. The issue is that in the wild, prerequisites look something like this
APL104 or equivalent, APL106 or equivalent
Basic Mathematics (Class 10 level)
APL104/APL105/APL108 EC 50
TXL111/TXL221 for uG students
ELL101 and ELL202 and (ELL211 or ELL231)
To be declared by Instructor
If you had a lot of people, you’d harvest these manually. If you had a small team of developers, you’d accumulate a bunch of heuristics and rules to parse. Since I’m a single developer, using an LLM and calling it a day seems best
Prior work
Surprisingly, I couldn’t find many papers which propose this task. This is probably an Information Extraction task, with a specific schema. Generalizing IE from task-specific models such as tagging/semantic parsing/relation extraction to models capable of handling generalized schemas seems to be a task called Universal Information Extraction [1], and there are some techniques for this [2].
In my opinion, this is a good research direction. Semi-automated, or fully automated extraction of data from unstructured sets, with:
- Either a focus on varying schemas, where the ability of models are not their accuracy on the task, but how accurately they are capable of adapting and generalizing to new schemas and structures, or
- A focus on LLMs generating the best schemas for the data on their own.
Considering the advances with LLMs, and considering how much unstructured data there is, this is somewhat similar to LLMs cleaning up data to train themselves, but in a more general context.
But enough playing Paul Graham. Let’s build something!
Not your Weights, Not your Brain
I initially tried using the perplexity API, but they kept declining my card. I then spent an hour and a half setting up Mistral-7B on my MBP. This is a good time to shout out to MLX, which is fast becoming the de-facto framework for ML on Apple Silicon. Just like everything Apple does: Metal instead of better OpenGL/Vulkan, Swift/Objective-C instead of C++, and MLX instead of PyTorch. Atleast MLX shipped with some very nice examples, which basically tell you how to quantize and run your mistral quickly on Mac. This was easy to set up, and fine-grained control over the prompt allowed me to cache the in-context examples beforehand, making inference fairly quick.
If you don’t have an apple silicon or NVIDIA GPU for inference, I later signed up for Together’s API, which also gives you $25 in free credits! That’s a good alternative.
With a model set up, we can now move to the prompt and task itself
Parsing at last
This was fairly simple if you know a bit of prompt engineering. You don’t even
need to take care of the Mistral Instruction tokens ([INST] and [/INST]),
as I got better results without them. For completeness, here was the prompt:
You need to parse a set of course prerequisites into logical expressions which can be parsed by a machine. The input format is in plaintext, and the output is a boolean expression within square brackets. If there is any confusion, choose the most unambiguous combination. Ignore "Or Equivalent", "Undergraduate" or any other qualifiers. ONLY include alphanumeric course codes, or EC values. EXACTLY FOLLOW THE FORMAT.
Prerequisites: APL104/APL105/APL108 EC50
Parsed: [(APL104 || APL105 || APL108) && EC50]
Prerequisites: APL106 or equivalent, APL321
Parsed: [APL106 && APL321]
Prerequisites: BBL131, BBL331 or Masters’ degree in
Parsed: [BBL131 && BBL331]
Prerequisites: CVL242 or Concurrent with CVL242
Parsed: [CVL242 || CVL242c]
Prerequisites: CVL281 and CVL282
Parsed: [CVL281 && CVL282]
Prerequisites: CVL282 or EC 75
Parsed: [CVL282 || EC75]
Prerequisites: To be declared by Instructor
Parsed: []
Prerequisites: CLL222, CLL352
Parsed: [CLL252 && CLL352]
Prerequisites: M.Tech: Nil; B.Tech: Instructor's permission
Parsed: []
Prerequisites: MCL140, APL106 or APL105, ESL200, ESL262,
Parsed: [MCL140 && (APL106 || APL105) && ESL200 && ESL262]
Prerequisites: (example here)
Parsed:
Note the extra concurrent example. Only the Civil Engineering department has this. Picking the examples required me to skim over the dataset and look for abnormalities. We don’t really care about similarity between the in-context and parsed examples, as we’re not doing an eval here.
This gave quite decent results, and took a bit under 1.5 hours to run on my machine for >5000 courses. With this done, the boring part was left.
Frontend
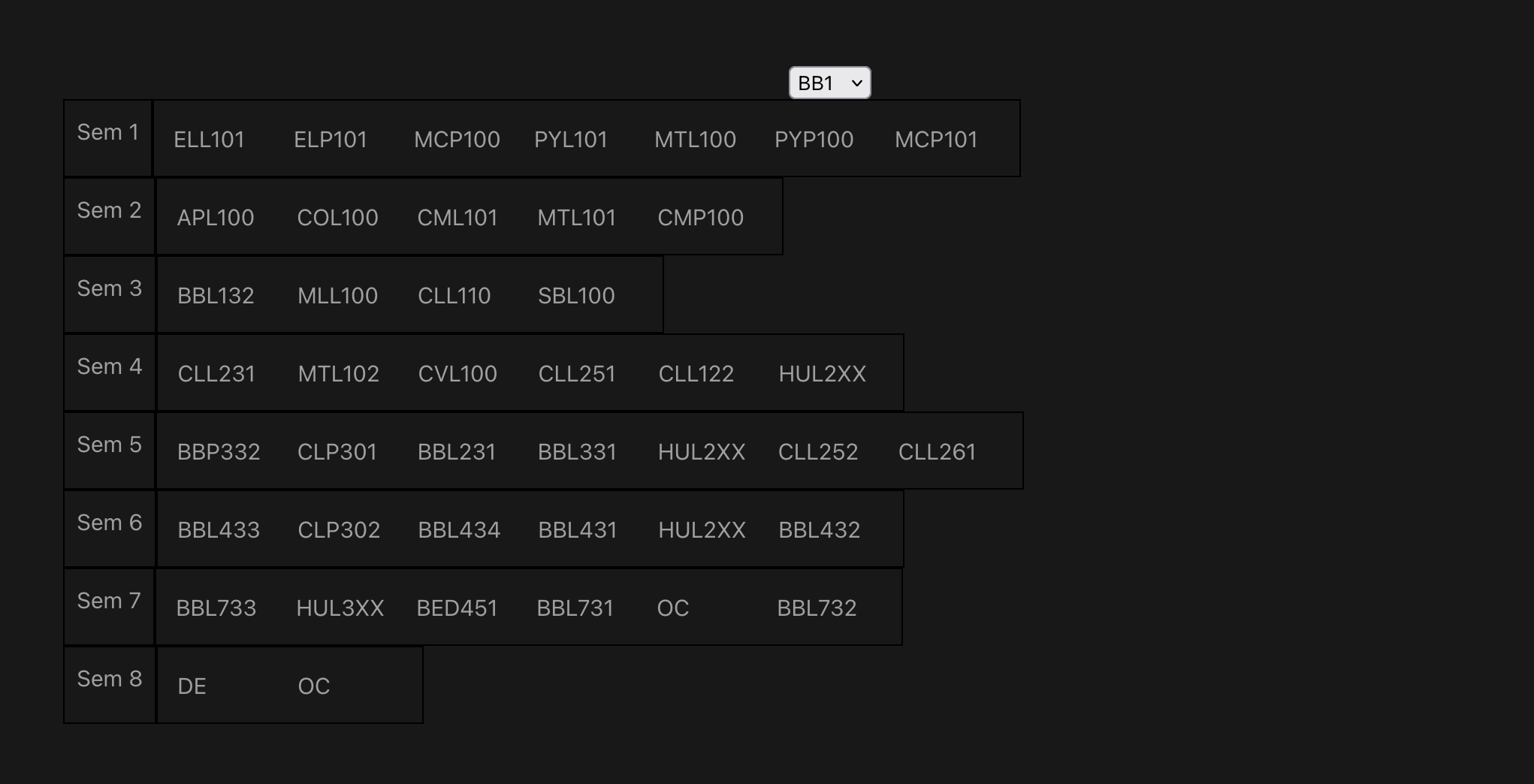
Kick starting any project with ChatGPT is a godsend, and should become standard practice at this point. The first version just loaded the JSON courses and displayed them on a table.
After a few improvements: adding Dragula for dragging/dropping courses and svg-dom-arrows for drawing dependency arrows, the plans looked a bit better.
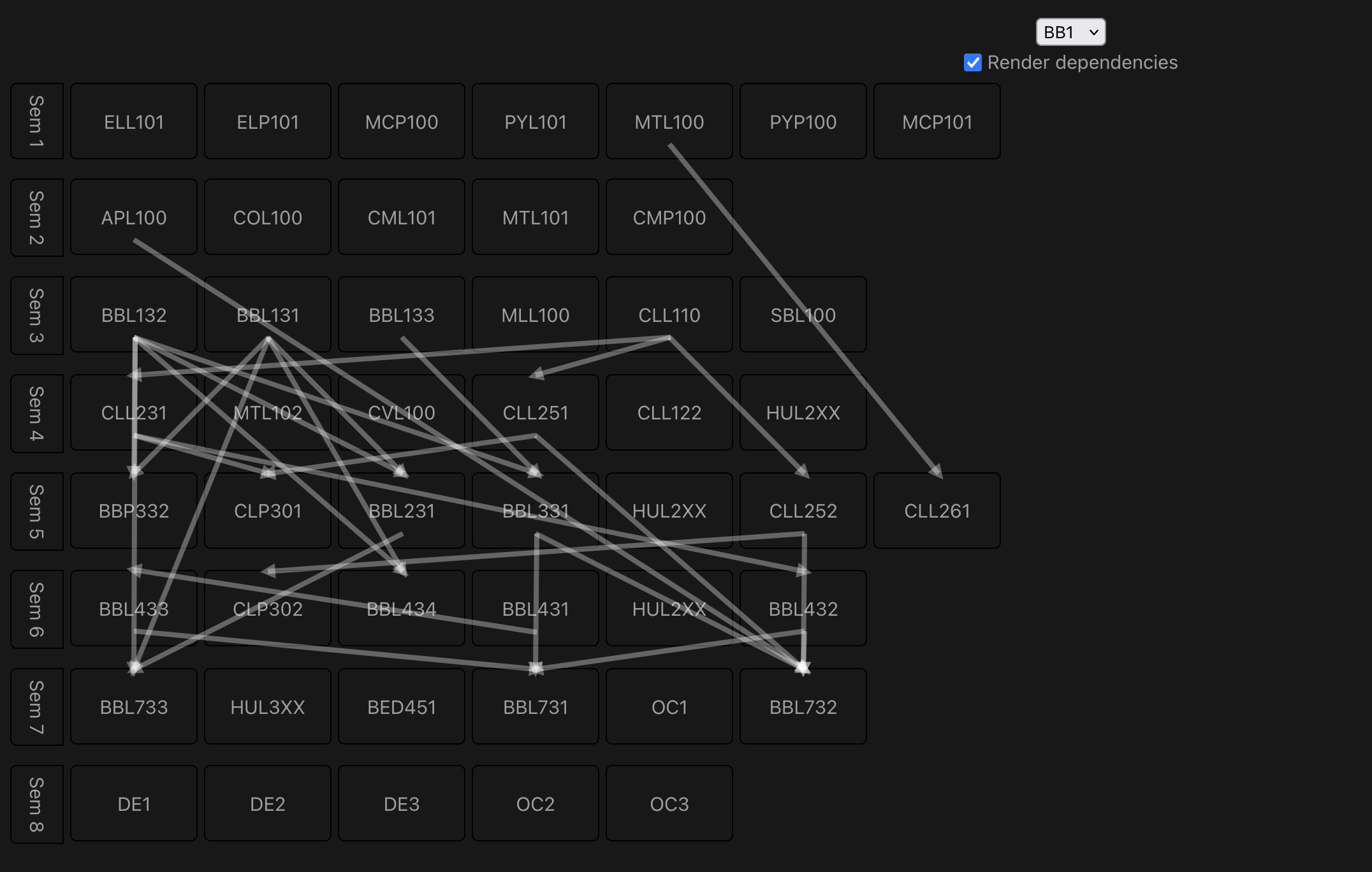
The theme is too dark, according to a friend, and there is too much darkness in the degree (a bit too realistic according to him)
What next?
Using jison, I also hacked up a small parser for parsing the course
dependency language
%{
function And(a, b) {
this.left = a;
this.right = b;
}
function Or(a, b) {
this.left = a;
this.right = b;
}
%}
%left AND OR
%start deps
%%
deps: START expr END {return $2;}
;
expr: expr AND expr {$$ = new And($1, $3);}
| expr OR expr {$$ = new Or($1, $3);}
| LBRACKET expr RBRACKET {$$ = $2;}
| TERM {$$ = yytext;}
| /* epsilon */
;
While the arrows as of now don’t use the OR dependencies in any way, this is something that would be fixed soon (maybe using different groups of colors for different conditions?). I’ll also need to allow checking off courses, saving and loading course plans, and adding available courses to your DE/OC/HUL slots. Further extensions would leverage slotting data. That data, while private, is much easier to parse and shouldn’t be too difficult to integrate.
However, there’s a course review due either next year or the year after that, and I’ve heard on the grapevine that there would be some major changes. In light of this, I don’t even know how useful this would be in the long term.
This was a fun project to hack around with, and while I’ll try to keep giving it some slices of my time whenever I get some, only time would tell how useful this is.
Final year, single rooms. Although his room is still next to mine ^_^ ↩︎