Breaking the HighLoad Orderbook Challenge
For roughly 48 hours, I had the “fastest orderbook” in the world.
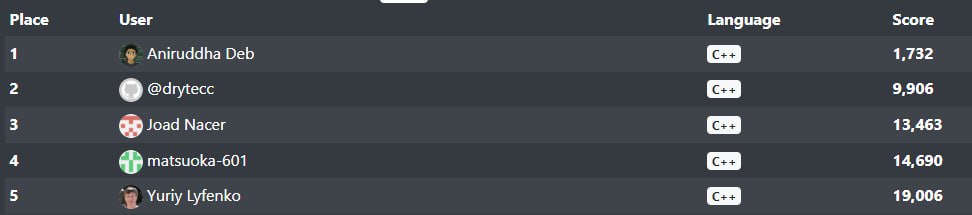
This is not photoshopped or modified using Inspect Element. My orderbook was so impossibly fast that it beat first place by 8000 points, in a challenge whose leaderboard has been open for almost four years now. The best part was it used your average vector-based level order book, not some AVX2 monstrosity optimized to death.
Unfortunately for this solution, it was like running the first four-minute mile: once you did it, everyone noticed, realized this could be done and that doing this doesn’t test how fast an orderbook is. The author ended up rewriting the generator, and my magic trick no longer worked.
So, are you watching closely?
The Pledge
If you’re not familiar with HighLoad, it’s a site where you join the community of the best software engineers and write the fastest code. Think of it like Kaggle, but solutions optimize for speed and not accuracy. While documentation regarding the site is sparse, Matt Stuchlik had previously written some notes on how to approach and solve the parse integers and count uint8 challenges. These are very good articles. I got my start to solving these problems from them. If you completely understand and break down the ideas implemented in them, you can easily break into the top 20 in every challenge.
By now I’ve tackled enough challenges to have a playbook ready to approach new problems, which goes like this:
- Create an input generator. For most problems taking random bytes, this is just
openssl rand 250000000 > input.bin. For problems taking ASCII input, more care is needed. - Create a baseline. This should be really simple, i.e. just mmap the input and implement the most naive algorithm you can think of.
- Come up with new ideas to implement. This can be done qualitatively, by thinking of new ideas or faster approaches, or quantitatively by using tools (perf, processor trace, uICA etc). The quantitative approach is only useful up to a certain level, after which it’s more research and hypothesis testing.
- Implement the idea and create a new submission.
- If you’re #1 on the leaderboard or out of energy and ideas, take a break and move on to a new problem. If not, go back to step 3.
Coming back to this challenge in particular, we have three main types of book updates:
- Inserts - add an offer to the orderbook, at a given price and size
- Deletes - delete the nth order in the book. The ordering is according to price-time priority
- Buys - lift n lots from the orderbook.
We need to process 1 million updates, and then lift 1000 lots from whatever orders are left. Seems simple enough to implement, and very reminiscent of the QuantCup challenge from roughly 15 years ago.
The Turn
The first thing I had to worry about was creating the input generator. For this, I needed to know the range of each of those four values and the rough distribution of operations. Highload lets you print to stderr and will show you the first 1000ish lines, so printing summary statistics for the input is doable. It was easy to make counters for each value which track the max and min, and print them out. I didn’t need more specific information, such as the histogram etc.
The final set of interesting statistics I gathered were as follows:
qty,min,max
price,815,4109
size,20,200
pos,0,1014
shares,200,2000
inserts 590570
deletes 389379
buys 20051
size is NOT always a multiple of 10
buy is NOT always a multiple of 10
max of max caps is 18
Running this multiple times made me realize that the price is always between 0 and 5000, size is always between 20 and 200, position is less than 1100 and shares are always between 200 and 2000. The max of max caps is the maximum queue depth, which is always less than 30 in my experiments. The ratio of inserts to deletes to bids is roughly 59:39:2 consistently.
Even without writing a test input generator, there are a few obvious optimization ideas if you look at these values closely:
- Fix the number of levels to 5000
- Use int8’s for size (with the possibility of SIMD’ing this - because max of max caps didn’t exceed 32 at any moment, so each level could be one SIMD vector)
- Maintain only the best 1100 offers, as we never delete beyond that and buying 1000 lots would always go through with these offers.
Idea 1 and 2 lend themselves fairly nicely to a simple level-based orderbook: have
a vector of vectors, and maintain the sum of elements in each vector. This is
also easy to SIMDify - while __m256i’s don’t make inserts any faster,
deletes on a level can be sped up with some clever shuffling, and finding said
level could be sped up with a segment/fenwick tree. I’m not saying I did all of
this immediately, but the first iteration of a vector-based book did speed up
my solution compared to the naive multiset-based one.
If you think about idea 3 more deeply, we would need to maintain a pointer to the 1100th order’s level all the time in order to do a compare against it. This pointer would need to be updated when a better offer is inserted, and I’d reckon that would make up >95% of the inserts, because most book activity happens at the top of book and not deep in the book. So, we only get rid of inserting 5% of inserts, which is not a super-significant speed up.
Can we do better?
The Prestige
In a more abstract sense, idea 3 tries to reduce the number of levels we track by eliminating updates we know are irrelevant to our final operation. This begs the question, what is the minimum set of updates I need to process if I know for a fact that I will buy 1000 orders at the end. To know more about this, we need to know which of the 100 million offers we eventually end up buying. Let’s give each update a unique ID (just sequentially increment a counter) and look at the top of book before we buy. This gives us the following results:
1047: [999974,77]
1048: [999964,154]
1050: [999859,56]
1054: [999846,100]
1055: [999848,144]
1056: [999844,179]
1057: [999847,41]
1060: [999947,167]
1062: [999841,107]
1064: [999954,191]
1070: [999839,54]
1073: [999999,44]
1085: [999949,71]
1087: [999865,24]
1098: [999943,66]
1107: [999869,106]
1145: [999987,180]
1155: [999927,130]
1163: [999875,62] [999892,178]
1170: [999877,29]
Bingo! The orders we lift are concentrated at the end. This is not a one-off, and multiple runs of this experiment always yielded orders with ID’s less than 1000 from the end. This makes sense, because orderbooks are more fluid at the top than at the bottom. To test if this hypothesis works, I decided to process the last three pages of input, and skip the rest.
off_t fsize = lseek(STDIN_FILENO, 0, SEEK_END);
size_t page_size = 4096;
size_t map_offset = (fsize - page_size*3) & ~(page_size - 1);
size_t map_length = (fsize - map_offset);
char* input = (char*)mmap(
0,
map_length,
PROT_READ,
MAP_PRIVATE | MAP_POPULATE,
STDIN_FILENO,
map_offset
);
int i=0;
while (input[i] != '\n') i++;
i++;
while (i < map_length) {
// read and process update
}
// buy 1000 lots and print cost
To get this test out quickly, I didn’t focus on optimization: I iterated over input one character at a time when processing it and did naive deletes and bids in my vector orderbook. An optimal solution would SIMD shuffle the input to decode it and use all the orderbook tricks I discussed above.
My first submission had debug logging to stderr in the hot loop that I forgot to remove when I submitted, and it’s score was <6000, 1.5x as fast as the best solution. Removing debug logging got me down to 1700. I was at the top of the leaderboard, and it was time to take a break.
Concluding thoughts
Simple maybe, but not easy.
~ Alfred Borden
I think what surprised me the most was not the fact that this worked, but that I was the first person to find this hack in the roughly four years that this challenge has been up. I’m not complaining, and am happy to be the first to discover this and share my findings.
As for what happened after this, other users immediately guessed I’m not processing most of the input. Yuriy (challenge author) then tested out a hypothesis of his own where he skipped input, and came to the same conclusion. There were a few tasks in the past, such as parse integers, where people discovered that processing the entire input is not neccessary. In those cases, a new generator was written, and the same was done for this challenge. You can see the new generator here.
While I think this is for the best, it’s hard to not be slightly disappointed. Though I do this for fun, and easy come easy go, IMHO solutions should either be:
- Completely deterministic, and pass user-submitted edge cases in addition to being scored when performance tested. This is similar to ‘hacks’ on CodeForces.
- Probabilistic, and pass the generator created when the problem was initially published. The generator should not be changed after that. Since it is hard to craft a perfect generator, complex generators should be open-sourced and put for review to the community for a short period whenever a new challenge is published. Such a change will move the focus solely to writing fast solutions.
As of now, you cannot write a top solution that’s not probabilistic in half of the callenges, and there is a very wide gray area between what’s legal and what’s not. There are no clear rules on the platform regarding what constitutes a ‘valid’ submission, and most decision making seems to be done by committee on a telegram group. It’s not bad, but this model won’t scale as more people join the platform. If a new user spends a lot of time and effort to find an inconsistency in a closed-source generator only to have their solution shot down because the community or the author decided that their solution didn’t satisfy unmentioned rules, it’s quite unfair and disincentivizes new people from competing. Someone who finds a loophole will likely sandbag and hide the fact that they’re not processing all of the input. At the very least, clear guidelines on what constitutes a valid problem and a valid solution should be written, for problem setters as well as solvers.
This shouldn’t be taken as a rant. I’ve learnt so much on the platform and from the community, and I hope some of this feedback does make it into v2 of the platform. I’m also looking forward to the blog system on v2, as knowledge grows when it’s shared. Many thanks to Matt Stuchlik, Joad Nacer and Grace Fuu for reading early drafts of this and providing feedback.