| Task | #8 |
|---|---|
| Position | 5 |
| Score | 32,906 |
| Best Score | 23,635 |
| Points | 0.718 |
Problem Statement
You have a data stream of uint32 numbers in binary representation sending to STDIN. The byte order is little endian.
Try to find the median¹ for the shortest time.
Numbers quantity is 100 000 000.
¹ Median is the element with the number 50 000 000 (a[N/2])
Input Generator
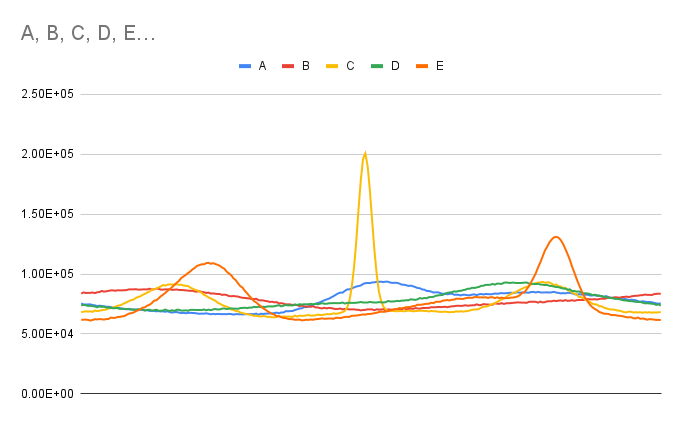
The input distribution is not uniform. My first solution sketch was to do a fast filter like TopK but on the middle of the range, and then filter out based on that range. This had an abysmal success rate. I think the leaderboards would look a lot more like TopK if that was the case, but it isn’t unfortunately. Even the distribution check confirms this.
The distribution, if I had to guess, is a mixture of normals over time. Something like this:
def generate(t, mu, sigma, acc):
if t == 100_000_000:
return acc
else:
acc.append(random.gauss(mu, sigma))
return generate(t+1, evolve_mean(mu, t), evolve_variance(sigma, t), acc)
where evolve_mean and evolve_variance could be as simple as:
def evolve_mean(mu, t):
if t % 100_000 == 0:
return random.randint(min_mu, max_mu)
return mu
or fairly complicated. I’d have to do some distribution fitting like I did in arithmetic expressions to find out.
Solution Sketch
Subsample one cacheline (16 numbers) every 1025 samples, and build a frequency counts histogram. I used 2048 bins, try to get this to fit in L1 because you’d need fast random access when incrementing. AVX2 does not have vpscatterd, that would’ve made it faster. Saturate your execution ports; I had two histograms that were added to in parallel, and the loop for adding the 16 numbers was unrolled. Combine the histograms in the end.
Use this histogram to construct a tight bound for the median, then go through each sample and reject/accept numbers that fit in the median. Keep a counter of the number of elements below and above the range. The fast path is vector bounds check and reject, and if that fails add to a vector using a slow path.
In the end, use quickselect on the vector of candidate medians to select the median element, based on the count of numbers below/above the acceptance range.
Thoughts
The bottleneck is going through all samples, and the only way I think that could be made faster is tighter bounds and better Memory Access. For tighter bounds, I’d have to look into the time evolution of the input generator distribution, and probably come up with some distribution estimation, instead of the strided subsampling I do right now.